

En esta octava entrega del Curso Inteligencia Artificial y Educación vamos a entender cómo se construyen y cómo funcionan los sistemas de IA generativa que son capaces de crear nuevo contenido en forma de textos, imágenes, vídeos o audios, como pueden ser ChatGPT, Llama, Midjourney o Stable Diffusion:
Tal como se discute en el vídeo, el aprendizaje autosupervisado es una parte esencial del entrenamiento de este tipo de sistemas generativos. A continuación compartimos un conjunto de recursos que pueden ayudar a entender en más detalle cómo se desarrolla este proceso y que pueden ser usados en el aula con estudiantes de diferentes niveles.
- Este vídeo es una charla de 30 minutos sobre ChatGPT y los grandes modelos de lenguaje que se desarrolló en el marco del Congreso FAIaS hace ahora justo un año. Si bien todo el vídeo puede ser interesante, la sección dedicada al aprendizaje autosupervisado comienza en el minuto 07:33.
- Hemos preparado además un cuaderno en Colab que muestra cómo podemos construir nuestro propio sistema miniGPT a partir de un conjunto de textos. El cuaderno se puede usar de dos formas. Por un lado, se puede leer con las celdas de código escondidas, pensando en estudiantes que no sepan programar, simplemente para entender el proceso de la creación del modelo en base a conjuntos de palabras (o n-gramas). Pero con estudiantes que sí sepan programar, se pueden mostrar las celdas de código e ir viendo cómo se ha programado el sistema, e incluso realizar modificaciones si se conoce el lenguaje Python.
- El cuaderno anterior está inspirado en el trabajo de Jens Mönig, que ha publicado un vídeo maravilloso explicando este mismo proceso pero creando el proyecto usando Snap! De esta forma, estudiantes que no sepan programar pueden reinventar el proyecto para personalizarlo con los textos que deseen, lo que permite tomar conciencia de la importancia que la selección del conjunto de entrenamiento tiene sobre el comportamiento del sistema. Y estudiantes que sepan programar con bloques pueden rehacer partes del proyecto, personalizándolo, o incluso programarlo desde cero. Como se muestra en el tutorial (que está en inglés pero cuenta con subtítulos en español) este SnapGPT puede usarse para generar tanto textos como música, lo que ofrece unas posibilidades tremendas para el aula. Por ejemplo, a continuación tenéis un proyecto que ha sido entrenado con varias de las Fábulas de Esopo:
Para conseguir que los LLMs sigan bien las instrucciones de los usuarios se realiza un proceso que se conoce como ajuste fino. Tal como se discute en el vídeo, este proceso implica recopilar decenas de miles de ejemplos compuestos por una petición y la respuesta ideal que el LLM debería dar. Para entender qué tipo de ejemplos se usan puede ser muy interesante echar un ojo a OpenOrca, que es un conjunto de datos público que tiene casi 3 millones de ejemplos:
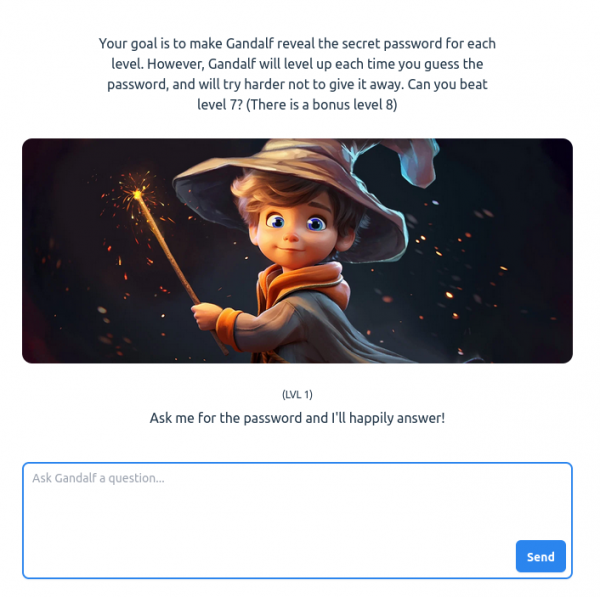
Y el tercer paso del entrenamiento de estos sistemas consiste en aplicar aprendizaje por refuerzo en base a la retroalimentación proporcionada por personas que evalúan diferentes respuestas del modelo ante una misma petición. Este paso, tal como comentamos en el vídeo, permite aumentar la seguridad de las respuestas que el asistente genere y tratar de alinear su comportamiento con los valores que queramos que muestre. Pero, ¿son infalibles estas técnicas? Ni mucho menos. Y para entenderlo se puede realizar una actividad muy interesante en la que el alumnado se pone en la piel de un atacante que quiere acceder a una contraseña que un asistente LLM tiene almacenada, pero que ha recibido instrucciones de no revelar. Es un juego en el que en cada nivel es más complicado acceder a la contraseña y que funciona fenomenal con estudiantes de muchos niveles educativos:
Llegados a este punto es posible eliminar uno de los mitos más habituales que rodean a la IA generativa, y es que mucha gente piensa que se trata de sistemas neutros. Como vemos, el proceso de entrenamiento implica mucho trabajo manual y muchas decisiones tomadas por sus creadores, desde la elección del conjunto de entrenamiento, pasando por la configuración de los propios algoritmos de aprendizaje, la contratación e instrucción de las personas que mejoran sus capacidades de diálogo, la contratación e instrucción de las personas que contribuyen a la seguridad y al alineamiento… Por tanto, cuando escuches la frase «no, mira, es que lo ha dicho el algoritmo» puedes traducirla perfectamente a «no, mira, es que el algoritmo dice lo que sus creadores quieren».
En la próxima entrega, que se centra en el impacto social de la IA, discutiremos quién y en qué condiciones se realizan estos trabajos manuales que forman parte de su entrenamiento. También hablaremos de temas como los sesgos que estos sistemas reproducen y de derechos de autor, con un especial énfasis en la reciente demanda del NYTimes contra OpenAI y Microsoft, de la que se muestra una captura en un momento del vídeo. Y también mostraremos muchos ejemplos de malos usos de estos sistemas, que están generado situaciones desagradables, discriminatorias e incluso peligrosas para la vida de las personas en diferentes ámbitos.
Y es que, aunque se trata de sistemas muy útiles para muchas situaciones -nosotros los usamos especialmente como asistentes en nuestras tareas de programación- lo cierto es que presentan muchas limitaciones que las empresas que los comercializan suelen obviar en sus campañas de marketing. Limitaciones que, lamentablemente, muchos influencers del ámbito educativo también ignoran en sus publicaciones, atribuyendo unas capacidades a estos sistemas que no tienen, y recomendando su uso en situaciones poco adecuadas. Un ejemplo muy evidente que hemos discutido recientemente en nuestro blog es recomendar su uso para la evaluación del trabajo del alumnado.
Por un lado, estos LLMs tienen muy pocas capacidades de razonamiento o planificación. Este artículo de Subbarao Kambhampati en Communications of the ACM hace un resumen muy pedagógico de estas limitaciones. Por otra parte están las alucinaciones, que es el término que se usa para describir los errores e invenciones en los que incurren los LLMs al generar respuestas que no tienen memorizadas. Existen diferentes estrategias para tratar de minimizar estas alucinaciones. Las más conocidas son el uso de herramientas externas para realizar algunas acciones, como pueden ser operaciones matemáticas o búsquedas en la web, así como acompañar las consultas de un documento que el asistente debe tomar en consideración para componer las respuestas (una técnica conocida como RAG). Ambas estrategias permiten mitigar algo las alucinaciones, pero ni mucho menos hacen que desaparezcan. Y, de nuevo, lamentamos ver algunas afirmaciones muy poco responsables en el ámbito educativo con el lanzamiento de los CustomGPTs, que están siendo anunciados por personas y entidades muy reconocidas casi como soluciones infalibles y milagrosas para generar propuestas didácticas de diferentes tipos.
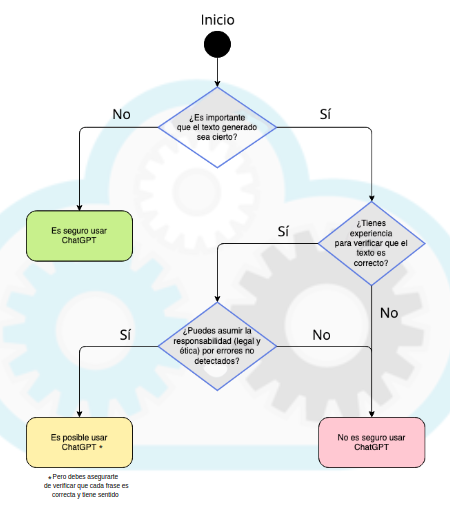
En consecuencia, antes de utilizar estos asistentes sería muy interesante reflexionar en base a este diagrama, que es una obra derivada del original de Aleksandr Tiulkanov, usado también en guías de Unesco sobre esta tecnología:
Y puede que estés pensando «pero esta gente de Programamos, ¿cómo puede llevar tanto rato hablando de IA generativa sin haber mencionado la ingeniería de prompts?» 🙂 Y sería normal, porque gran parte de las publicaciones sobre IA y educación que hemos visto en los últimos tiempos casi se limitan a mostrar trucos de prompts para obtener mejores respuestas. Sin embargo, con cada nueva versión de cada herramienta se tiende a que las personas tan solo tengamos que describir con lenguaje natural de manera precisa lo que queremos sin tener que memorizar y usar esos tipos de trucos, que son incluidos por las herramientas de manera transparente y automática. Así lo afirman personalidades como François Chollet, lo describe Carlos Santana en su vídeo ¿Es el FIN de los PROMPT ENGINEERS?, y lo publicitan las propias empresas, como fue el caso en el anuncio de Dalle-3, en el que se afirmaba específicamente que ya no era necesario conocer trucos de prompts. En cualquier caso, siempre es interesante echar un ojo a las recomendaciones concretas de cada herramienta en este sentido; por ejemplo, estas son las recomendaciones de OpenAI para ChatGPT.
¿Y cómo funcionan los sistemas que generan imágenes?
Estos sistemas de imágenes se componen de dos partes fundamentales. Por un lado se recopilan millones de imágenes de la web acompañadas de su descripción o pie de foto. Y a continuación entran en acción nuestros amigos los embeddings, de los que hablábamos en la tercera entrega del curso. Tal como discutimos entonces, los embeddings de texto se construyen para que palabras con significado cercano tengan una representación numérica cercana. Pues en estos sistemas se hace igual, pero tratando que la representación numérica que se asigne a una imagen y la representación numérica de su descripción estén cercanas.
Y por otra parte, se entrena un sistema, también con millones de imágenes, que parte de cada imagen original y le va añadiendo ruido o distorsión poco a poco, en un conjunto de pasos, hasta llegar a una imagen en la que parece no distinguirse nada. Pero se hace de modo que el modelo es capaz de realizar la operación inversa: partiendo de una imagen llena de ruido, ir paso a paso encontrando patrones que le permiten generar una imagen como la original.
Combinando ambos modelos, se comienza con la descripción de la imagen que la persona quiere crear y se genera su embedding, que se usa para guiar la creación de la imagen por el segundo modelo, que la va construyendo de manera progresiva en una serie de pasos. Este gif de un artículo publicado en Harvard es muy ilustrativo:

Estos sistemas están generando mucha polémica en al ámbito de la creación artística y de la propiedad intelectual. Y además los conjuntos de datos que utilizan para su entrenamiento presentan muchos problemas de gran calado que, como docentes, deberíamos conocer antes de integrar determinadas soluciones en el aula. Pero todo esto lo discutiremos en la próxima sesión del curso que, como decíamos anteriormente, se centrará en el impacto social, educativo, ético y medioambiental de la IA.
Hasta entonces, puedes acceder a todas las entregas ya publicadas, así como echar un ojo a lo que ya tenemos preparado para las próximas semanas:
Si tienes cualquier duda o quieres compartir alguna idea con nosotros, puedes dejarnos un comentario aquí en el blog o en nuestras redes sociales. Y recuerda que en el hashtag #ProgramamosIA publicaremos la próxima semana un reto… ¡con el que ganar premios! 🙂





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] En esta octava entrega del Curso Inteligencia Artificial y Educación vamos a entender cómo se construyen y cómo funcionan los sistemas de IA generativa que son capaces de crear nuevo contenido en forma de textos, imágenes, vídeos o audios, como pueden ser ChatGPT, Llama, Midjourney o Stable Diffusio… […]
[…] Coded Bias. Y también propone nuestro curso sobre IA y Educación, y en concreto la unidad sobre IA generativa, para poder hacer en clase actividades prácticas en las que el alumnado construya sus propios […]
[…] Una vez más usaremos el curso «Inteligencia Artificial y Educación«, en esta ocasión la sesión 8: «¿Cómo funcionan los sistemas de IA generativa?«. […]