

En esta cuarta entrega del Curso Inteligencia Artificial y Educación vamos a centrarnos en comprender cómo los ordenadores son capaces de entender nuestros textos o nuestras instrucciones orales:
Habrás visto en el vídeo que muchos de los ejemplos incluyen una referencia a cohere,com, y es que nos hemos basado en el currículo de la LLM University de cohere, liderada por el gran científico de IA Luis Serrano. Para quien tenga interés en profundizar más sobre los conceptos tratados en esta entrega, la LLM University ofrece muchos recursos muy interesantes.
En el vídeo comentamos que los embedding de aplicaciones reales suelen tener cientos o miles de dimensiones. Con la biblioteca eCraft2Learn para Snap! -que presentamos en la anterior sesión del curso– podemos hacer cosas muy interesantes con los embeddings. Por ejemplo, podemos visualizar cuál es el vector de números que se asigna a una palabra:
Como vemos, estos embeddings tienen 300 dimensiones. Fueron creados por un equipo de investigación de Facebook. Un poco más adelante en el curso discutiremos en detalle cómo se construyeron mediante técnicas de aprendizaje automático, pero ya podemos adelantar que crearon modelos de 157 idiomas diferentes utilizando todos los artículos de la Wikipedia. Aunque eso representa más de mil millones de palabras, también utilizaron miles de millones de palabras más que descargaron rastreando sitios web de internet. Y básicamente lo que midieron fue qué palabras aparecían cerca de otras en todos estos textos, como aproximación al significado de las mismas. Aunque los embedding originales tienen la representación numérica de un millón de palabras de cada idioma, la biblioteca de eCraft2Learn solo incluye las 20.000 palabras más comunes de 15 idiomas, incluyendo el español.
Como estos embeddings son un conjunto de 300 números, se pueden hacer operaciones aritméticas con ellos. Por ejemplo, para calcular cuál es la palabra más cercana a otra:
Esta biblioteca ofrece un montón de oportunidades para el aula. Por ejemplo, se puede calcular qué palabra está a mitad de camino de otras dos -¿qué palabra crees que estará entre mañana y noche?-, o incluso se pueden utilizar embeddings para resolver analogías del tipo hombre es a mujer lo que rey es a ¿?, cuyo resultado debería ser reina.
Como defienden Touretzky y Gardner, en nuestra cultura los diccionarios y los tesauros son la codificación tradicional del significado de las palabras, pero la tecnología informática nos ofrece este nuevo tipo de representación, los embeddings, que son la base de muchas de las aplicaciones de lenguaje natural con las que interactuamos habitualmente, como traductores automáticos, asistentes digitales para el hogar o sistemas de chatbot. Y permitir al alumnado experimentar por su cuenta con esta nueva representación es el equivalente de nuestro tiempo a aprender a explorar un diccionario, enriqueciendo su apreciación por el lenguaje.
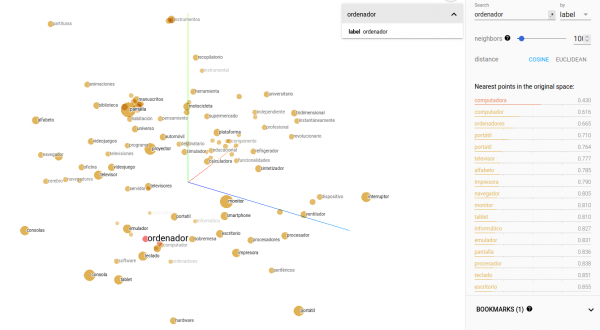
Existen muchas visualizaciones online que permiten explorar vocabularios y experimentar con analogías de aritmética de vectores. Os dejamos a continuación una de estas demos, con la que seguro que te vas a sorprender al ver qué palabras aparecen en el entorno de ciertas palabras (por ejemplo, busca las palabras chico y chica), y con la que puedes tratar de predecir la posición de una palabra tras haber visualizado previamente la posición de otras palabras y la distancia entre ellas.
Para terminar, en el vídeo se muestra cómo comparar la similitud semántica de diferentes frases usando un espacio de HuggingFace con el que también puedes hacer actividades muy interesantes en el aula:
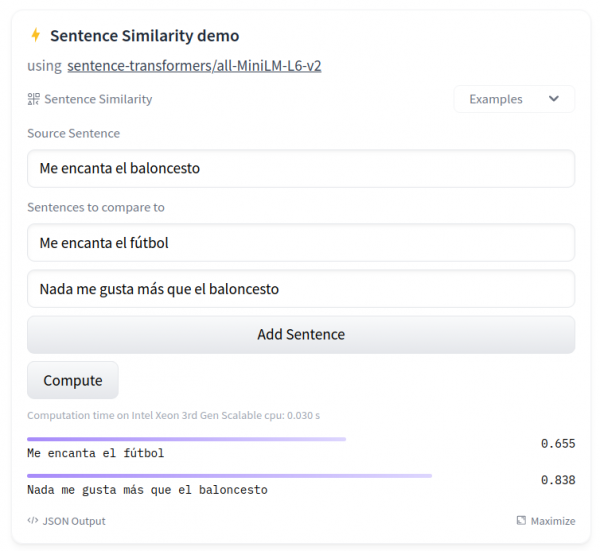
Ya sabes que HuggingFace es el sitio de referencia en el mundo de la IA -como te contábamos en la primera sesión del curso– así que si todavía no tienes cuenta quizá sea buena idea crearte un usuario en la plataforma.
¡Y hasta aquí con la sesión de hoy! 🙂 Recuerda que puedes acceder a todas las entregas ya publicadas, así como echar un ojo a lo que ya tenemos preparado para las próximas semanas:
Si tienes cualquier duda o quieres compartir alguna idea con nosotros, puedes dejarnos un comentario aquí en el blog o en Twitter con el hashtag #ProgramamosIA.¡Nos vemos la semana que viene!





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] acompañadas de su descripción o pie de foto. Y a continuación entran en acción nuestros amigos los embeddings, de los que hablábamos en la tercera entrega del curso. Tal como discutimos entonces, los embeddings de texto se construyen para que palabras con […]
[…] actividad que se ha desarrollado en el taller está basada en la sesión 4 del fabuloso curso «Inteligencia Artificial y Educación» de la Asociación Programamos. Os […]