

En esta sexta entrega del Curso Inteligencia Artificial y Educación vamos a discutir cómo los ordenadores son capaces de aprender automáticamente a partir de datos:
Como se indica en el vídeo, el enfoque «bottom-up», de abajo a arriba, propone que los ordenadores aprendan automáticamente a partir de la experiencia y la observación. Por eso, a este enfoque también se le llama aprendizaje automático, o machine learning en inglés. Para que el aprendizaje automático pueda funcionar bien hacen falta datos, y es por ello que este enfoque ha comenzado a despegar en paralelo con el big data, como ya mencionábamos en la primera sesión del curso.
Gracias al aprendizaje automático es posible resolver muchos tipos de problemas para los que resulta complicado, o incluso imposible, definir a mano las reglas para su solución. Por ejemplo, imagina que quisieras definir las reglas para detectar en una imagen si una persona lleva puesta una gorra. Piénsalo un momento. Sería realmente complejo, ¿verdad?. Y sin embargo, como veíamos en el vídeo, resulta muy sencillo resolver este problema usando aprendizaje automático.
En los últimos años, los grandes avances que se han producido en el mundo de la IA los han protagonizado sistemas de aprendizaje automático. Tanto es así que muchas personas utilizan ambos términos como si fueran intercambiables. Sin embargo, el aprendizaje automático es un subconjunto del amplio campo de la IA. Y aunque permite resolver muchos problemas, tiene también limitaciones. Por ejemplo, a pesar de las muchas capacidades de los grandes modelos de lenguaje como GPT4, estos sistemas tienen dificultades para aprender de los datos de entrenamiento cosas como que si la persona A es la madre de B, entonces esto implica que B es hija de A. (Aunque esto lo discutiremos con mucha más profundidad en una entrega posterior).
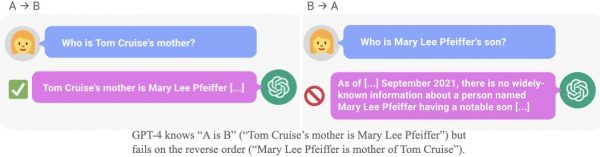
Sin embargo, con el enfoque «top-down», de arriba a abajo, que es el enfoque que tuvo mayor protagonismo en el mundo de la IA durante décadas, ese tipo de problemas se resuelve de forma muy sencilla definiendo una serie de reglas que se aplican sobre un conjunto de datos. En la imagen siguiente puedes ver una captura de un programa PROLOG, que es un lenguaje de programación muy utilizado en IA:
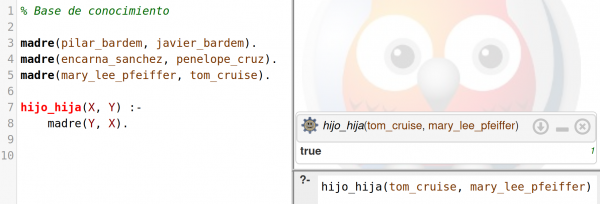
Así que es muy probable que los sistemas que veamos en los próximos años combinen técnicas «top-down» y «bottom-up», por lo que es interesante que el alumnado tenga experiencias prácticas con ambos enfoques. Si quieres hace cosas en clase con PROLOG puedes usar el entorno SWISH, que permite trabajar online sin que tengas que instalar nada en los equipos y ofrece muchos ejemplos para dar los primeros pasos. Nuestro amigo Juan David Rodríguez nos ha compartido este breve manual de PROLOG que también puede ser de ayuda.
Pero en esta sesión nos vamos a centrar en el aprendizaje automático. Y en concreto en el aprendizaje supervisado, que como decíamos en el vídeo, es el más habitual en la mayoría de sistemas de IA que usamos hoy día. Y, tal como afirman autores como Andrew Ng, parece que el aprendizaje supervisado seguirá siendo el tipo de aprendizaje automático con mayor valor en los próximos años:
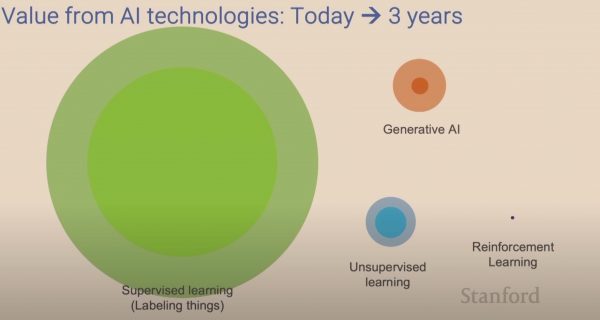
El aprendizaje supervisado (en verde) seguirá siendo la tecnología de IA con mayor impacto en los próximos años
El aprendizaje supervisado requiere contar con un conjunto de datos de entrenamiento que esté etiquetado. Es decir, que los datos de entrenamiento incluyen tanto las entradas como las salidas correctas. Por eso se llama supervisado, porque requiere que alguien experto en la materia supervise el etiquetado de los datos de entrenamiento. Y a partir de estos datos, un algoritmo de aprendizaje construye un modelo mediante la localización de patrones.
Como comentamos en el vídeo, existen muchos algoritmos que se pueden utilizar para localizar estos patrones en los datos y construir un modelo. Uno de los algoritmos más sencillos de entender es el de los K vecinos más cercanos (KNN, de sus siglas en inglés). Este algoritmo memoriza todos los datos de entrenamiento y cuando tiene que clasificar un nuevo elemento comprueba de qué tipo son los vecinos más cercanos. Así, si hay más vecinos de una cierta clase, establece que el nuevo elemento debe ser de esa clase. Podemos verlo en acción en el siguiente proyecto Scratch, en el que lo primero que tenemos que elegir es el número de vecinos que se van a considerar, que es el parámetro K de este algoritmo:
https://scratch.mit.edu/projects/925194674/
En la Conferencia internacional sobre pensamiento computacional y educación de 2019, celebrada en Hong Kong, se presentó una actividad muy interesante para comprender cómo funciona este algoritmo de los K vecinos cercanos trabajando de manera desconectada. Y el equipo de CodeINTEF, en base a esa actividad, elaboró un recurso para el aula que tiene todo lo necesario para aplicar el algoritmo KNN (con K=1) para reconocer imágenes de diferentes figuras célebres de la ciencia de forma desenchufada. ¡Muy recomendable incluso en primaria!
Habrás visto que en el vídeo mostramos el sitio web Machine Learning Playground, que es un sitio ideal para aprender los detalles de diferentes algoritmos que se utilizan en el aprendizaje supervisado. La web permite añadir puntos de distintas clases y ver cómo se construyen modelos usando los diferentes algoritmos, que además puedes personalizar estableciendo valores para sus parámetros. Por ejemplo, en KNN puedes ir cambiando el valor de K y ver cómo se modifica el resultado. Pero el sitio web también ofrece una explicación sencilla del funcionamiento de cada algoritmo, que consideramos que recoge los puntos más importantes y que puede ser de interés para estudiantes de bachillerato y FP.
Uno de los algoritmos con los que puedes jugar en el ML Playground es el perceptrón, que sería una neurona artificial; y también puedes jugar con una red neuronal con varias capas y varias neuronas. Pero estamos seguros de que vas a aprovechar más y a sacarle todo el jugo a estas demos si antes has visto los vídeos del gran Carlos Santana en los que explica cómo funcionan las redes neuronales:
Para estudiantes de bachillerato y FP el Playground de TensorFlow, que también se muestra en un momento del vídeo, puede ser muy interesante.
Y todo esto está muy bien como introducción y punto de partida, pero como se aprende de verdad sobre aprendizaje supervisado es construyendo tus propios modelos. Y si además programas aplicaciones que usen estos modelos, vas a poder entender las posibilidades y límites de este tipo de sistemas, permitiéndote tener una visión mucho más crítica y realista frente a noticias y publicaciones en el futuro.
La herramienta que nos parece más interesante para el aula es, sin duda, LearningML. Se trata de una solución que ofrece muchas posibilidades para distintos niveles educativos, que está basada en software libre, que puedes utilizar sin registro, tanto de manera online como en tu equipo, y que no rastrea ni usa datos de ningún tipo sobre tus estudiantes. Desde el punto de vista de las directrices éticas sobre el uso de la IA en educación de la Comisión Europea, que discutíamos en la segunda entrega del curso, no conocemos otra solución que se acerque a LearningML. Y como os hemos contado a lo largo de los últimos años, se ha utilizado con mucho éxito en diferentes investigaciones para medir su eficacia en el ámbito educativo.
Para comenzar a utilizarla en clase, nuestra recomendación es empezar visualizando algunos de los vídeotutoriales de la herramienta, que te van a guiar en la construcción de distintos tipos de modelos que utilizan textos, imágenes o números como datos de entrenamiento. Y además vas a aprender a programar proyectos Scratch que hacen uso de estos modelos.
A continuación, creemos que es muy interesante comenzar haciendo alguna de las actividades guiadas propuestas:
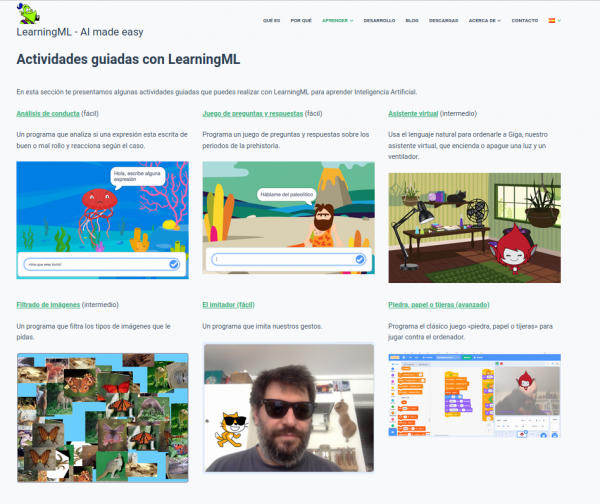
Y ya estaríais listo para poder trabajar en proyectos que resuelvan problemas del entorno y del interés del alumnado aplicando el aprendizaje automático para construir un modelo que luego se usa en una aplicación Scratch.
LearningML es una herramienta que está siendo desarrollada en España bajo el liderazgo de Juan David Rodríguez. Hay un vídeo muy bonito en el que el propio Juan David explica cómo nació LearningML, los retos a los que se ha enfrentado durante su desarrollo, y cómo se imagina el futuro del proyecto. Creemos que conocer estos detalles es una oportunidad muy interesante que no siempre tenemos a nuestra disposición, así que esperamos que lo disfrutes: enlace al vídeo de LearningML (a partir del minuto 2:55:00).
Para terminar, quizá el alumnado de FP de familia informática y comunicaciones podría ir un paso más allá construyendo sus propios modelos programando con Python y apoyándose en bibliotecas como scikit-learn. Para ello, en el MOOC de Inria sobre aprendizaje automático puedes encontrar multitud de conjuntos de datos, cuadernos Jupyter y retos para llevar directamente al aula. ¡Una verdadera joya!
¡Hasta aquí con la sesión de hoy! Reconocemos que ha sido una entrega muuuy larga y con mucho contenido 🙂 Así que, para no agobiar a nadie y para que puedas disfrutarla sin prisas, en esta ocasión habrá 2 semanas de descanso hasta la próxima entrega. Y habrá también doble reto, que como siempre anunciaremos en Twitter con el hashtag #ProgramamosIA.
Recuerda que puedes acceder a todas las entregas ya publicadas, así como echar un ojo a lo que ya tenemos preparado para las próximas semanas:
Si tienes cualquier duda o quieres compartir alguna idea con nosotros, puedes dejarnos un comentario aquí en el blog o en nuestras redes sociales. ¡Mucho ánimo!





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}