

En el reciente artículo «¿Por qué la inteligencia artificial discrimina a las mujeres?«, Ricardo Baeza-Yates y Karma Peiró además de analizar la situación actual de muchos sistemas de aprendizaje automático que ofrecen resultados que perjudican a las mujeres, también presentan algunas iniciativas que tratan de evitar este tipo de discriminaciones.
Uno de los varios ejemplos que presenta el artículo es el del traductor automático de Google, en el que al traducir del castellano al turco y del turco al castellano, la frase cambia presentando estereotipos de género, tal como se puede ver en la imagen.
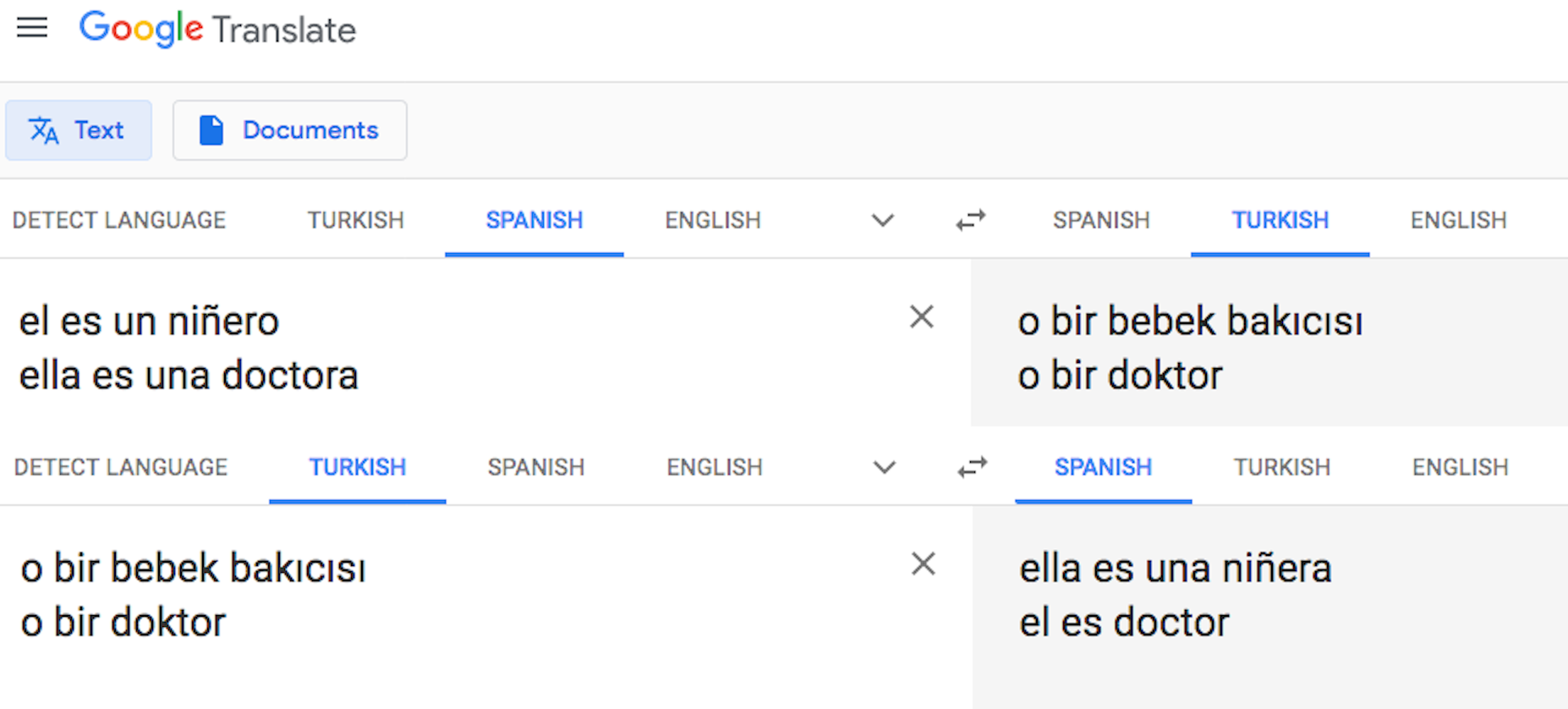
La explicación de este resultado es que, como en el idioma turco los pronombres no tienen género, el sistema usa la traducción más común de acuerdo a los datos con los que fue entrenado.
¿Qué se puede hacer para mitigar esta situación?
Si el problema se produce por los datos utilizados para entrenar al sistema, tal como discutíamos hace unos días en este artículo sobre el sistema COMPAS, parece claro que hay que trabajar en mejorar estos datos de entrenamiento. Baeza-Yates y Peiró lo explican así:
Esto implica que, por ejemplo, la mitad de las caras de una colección de datos sean de mujeres y que haya diversidad de ellas teniendo en cuenta la raza, color de pelo, expresiones, etc. En segundo lugar, que la categorización no tenga subcategorías con sesgo negativo, como bruja para nombrar a una mujer. Por último, debemos evitar que las personas que etiquetan caras no utilicen sus sesgos personales para perpetuar y amplificar estereotipos.
En el artículo se presenta FAIR, una solución que detecta patrones de discriminación en directorios que puedan favorecer o relegar a ciertos colectivos, y corrige esta discriminación incorporando un mecanismo de acción positiva.
Sobre la transparencia algorítmica
En el artículo se presenta el enfoque de Sandra Wachter que propone que empresas y administraciones públicas den “explicaciones contra factuales”:
La gente no quiere saber cómo se hizo el algoritmo, sólo por qué motivo fue discriminado/a o por qué no consiguió un trabajo”, explica Wachter. Y la manera más fácil, según la investigadora es respondiendo a preguntas simples: “¿Si ganara 10 mil euros más al año me habrían concedido la hipoteca? ¿Si tuviera una carrera universitaria, me habrían escogido para el trabajo?
Baeza-Yates y Peiró defienden que «si gobiernos e instituciones conceden la palabra a la ciudadanía, quizás avancemos hacia un mundo más justo» y animan a que la gente contribuya a procesos participativos como el de la Estrategia de Inteligencia Artificial de Cataluña.
No obstante, desde nuestro humilde punto de vista, la realidad actual es que la mayoría de la población no conoce lo suficiente sobre cómo funciona la inteligencia artificial como para cuestionarla, por lo que darle la voz a la ciudadanía no sería suficiente. Por ello defendemos desde hace años que todo el mundo debería aprender sobre algoritmos e inteligencia artificial en la escuela, para que toda la sociedad sea capaz de reconocer este tipo de sistemas, preguntar sobre ellos y cuestionarlos cuando su uso o comportamiento no sea el adecuado.
La imagen de cabecera es derivada de la foto
original de T. Chick McClure en Unsplash





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Deja tu comentario